PGKeeper: Building the bouncer we needed for Postgres








This is the story of why and how we built PGKeeper, a scalable and reliable service to support Figma’s rapidly growing products and database workload.
Share PGKeeper: Building the bouncer we needed for Postgres
Illustrations by Pete Gamlen
Figma has grown a lot over the past few years in terms of both features and users, which means our database layer has to contend with an onslaught of novel workloads and increased traffic. It was clear we were outgrowing PgBouncer, a lightweight and widely adopted PostgreSQL connection pooler. That led us to build PGKeeper, a new connection and load management service that replaces PgBouncer in front of our Postgres fleet. In this post, we walk through how we designed and rolled it out.
10,000-foot view of the database stack
PostgreSQL serves as the foundation of Figma's OLTP system. As Figma grew, we implemented horizontal Our nine month journey to horizontally shard Figma’s Postgres stack, and the key to unlocking (nearly) infinite scalability. How the Figma infrastructure team reduced potential instability by scaling to multiple databases.
How Figma’s databases team lived to tell the scale

The growing pains of database architecture

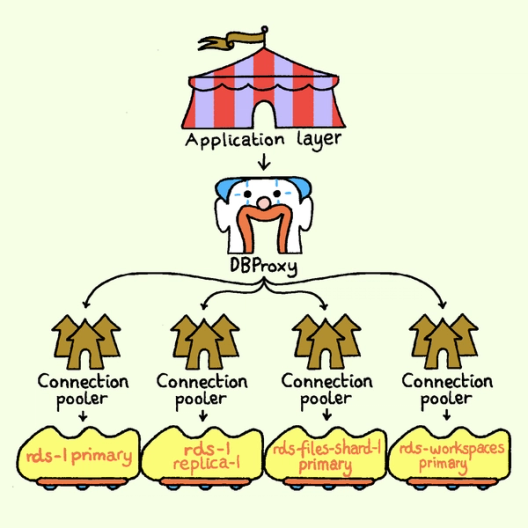
We built a request routing system called DBProxy to hide the sharding complexity from application code. It parses and analyzes the query, selects the appropriate target Postgres instances, and rewrites the query into one or more queries for each designated instance. From there, the request goes to a connection pooler (the component this post is about), which sits between DBProxy and Postgres. Each Postgres machine is served by a dedicated set of connection pooler replicas, establishing an n-to-1 relationship between the poolers and the underlying database.
Why PgBouncer was no longer enough
For several years, our system relied on PgBouncer, which performed adequately during Figma's earlier stages of growth. However, as our traffic grew and the reliability bar kept rising, we encountered the following limitations:
CoDel is a load-shedding algorithm that sheds work based on how long requests have been waiting, not how many are queued. Originally designed for network routers, the same idea applies anywhere a queue can get overwhelmed, including in front of a database.
- Scalability: PgBouncer's single-threaded architecture imposed a ceiling on vertical scalability. We scaled it horizontally by adding more replicas, but performance began to degrade due to load distribution skew.
- Load management: PgBouncer has no way to prioritize critical traffic above misbehaving, lower-priority traffic. Furthermore, the absence of a backpressure mechanism and support for sophisticated algorithms such as Controlled Delay (CoDel) prevents the graceful management of bursty load.
- Connection management: Postgres connections are resource-intensive. High connection churn or unbounded connection creation introduces significant reliability risks. PgBouncer lacks mechanisms to safeguard connections against both rapid creation and churn. Consequently, naive recovery after an overload incident can itself overwhelm the database, causing extended connection churn and prolonged, cascading overload across Postgres nodes.
- Extensibility and fine-grained control: As PgBouncer took on a more central role in our infrastructure, we needed the operational tooling we apply to our other critical services (deep observability, safe rollout via feature flags) and the ability to shape its behavior at the level of individual traffic types, with capabilities like admission control and fair resource sharing. Our experience maintaining even small patches to PgBouncer showed that extending it would carry significant maintenance costs.
Building PGKeeper
A natural question is why we didn't simply push connection pooling into DBProxy, our existing request router. The answer comes down to a numbers mismatch: We typically size each PostgreSQL instance's connection pool to about 100 connections, but we operate hundreds of stateless DBProxy replicas.
Distributing a small, fixed-size connection pool across a large number of stateless DBProxy instances is not feasible. Embedding connection pool management into each DBProxy replica would either violate the connection limit or require complex coordination across replicas.
The next candidate was PGCat, a modern multi-threaded PostgreSQL proxy that directly addresses PgBouncer’s vertical scalability limitations. But the extensibility problem from our PgBouncer evaluation applied here too: Adding the observability, feature flagging, and admission control we needed would require deep changes to PGCat’s core execution paths, changes unlikely to be accepted by upstream. In practice, this would force us to maintain a fork of PGCat, which would be a long-term burden.
So rather than adapting an existing proxy, we built our own. PGKeeper is a Go service that sits between DBProxy and Postgres. The name comes from the idea of a goalkeeper that protects bad traffic from overloading the system and protects connections from churning.
Unlike PgBouncer and PGCat, PGKeeper exposes a gRPC interface to clients. Each database query is treated as an independent request with metadata attached (e.g., traffic tier, user type, and request source) that PGKeeper uses to make decisions about how to handle it.
We built PGKeeper on top of PGX, a mature Go-based PostgreSQL toolkit. PGX provides the necessary primitives for connection management and protocol handling without constraining higher-level behavior, allowing us to implement custom load management and admission control logic cleanly.
Choosing Go aligned with our team’s expertise and broader infrastructure ecosystem. Its concurrency model and efficient resource usage also provided strong vertical scalability out of the box, directly addressing one of PgBouncer’s core limitations.
PGKeeper deep dive
PGKeeper replicas are deployed behind an NLB, and clients can establish multiple lightweight gRPC connections and distribute requests across them in a round robin manner. This decouples load balancing from the stateful nature of PostgreSQL connections and enables more even load distribution across PGKeeper pods. Each PGKeeper serves only a single Postgres instance, with multiple replicas deployed per instance across Kubernetes clusters for high availability.
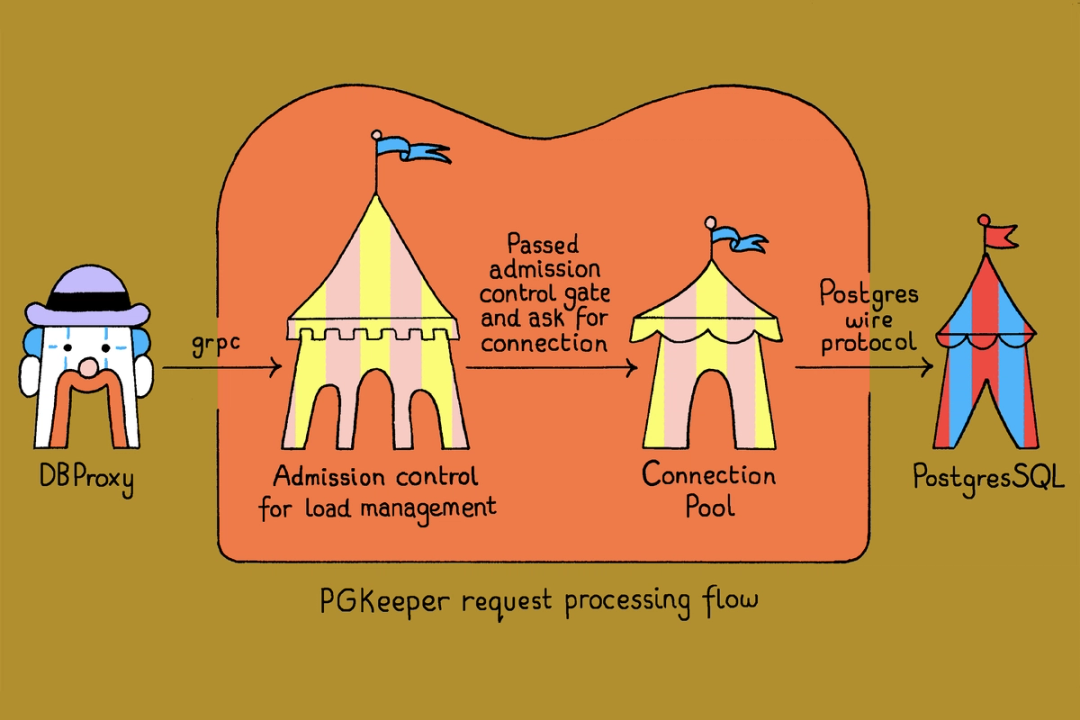
At runtime, a request lands on one of the replicas and proceeds through three stages:
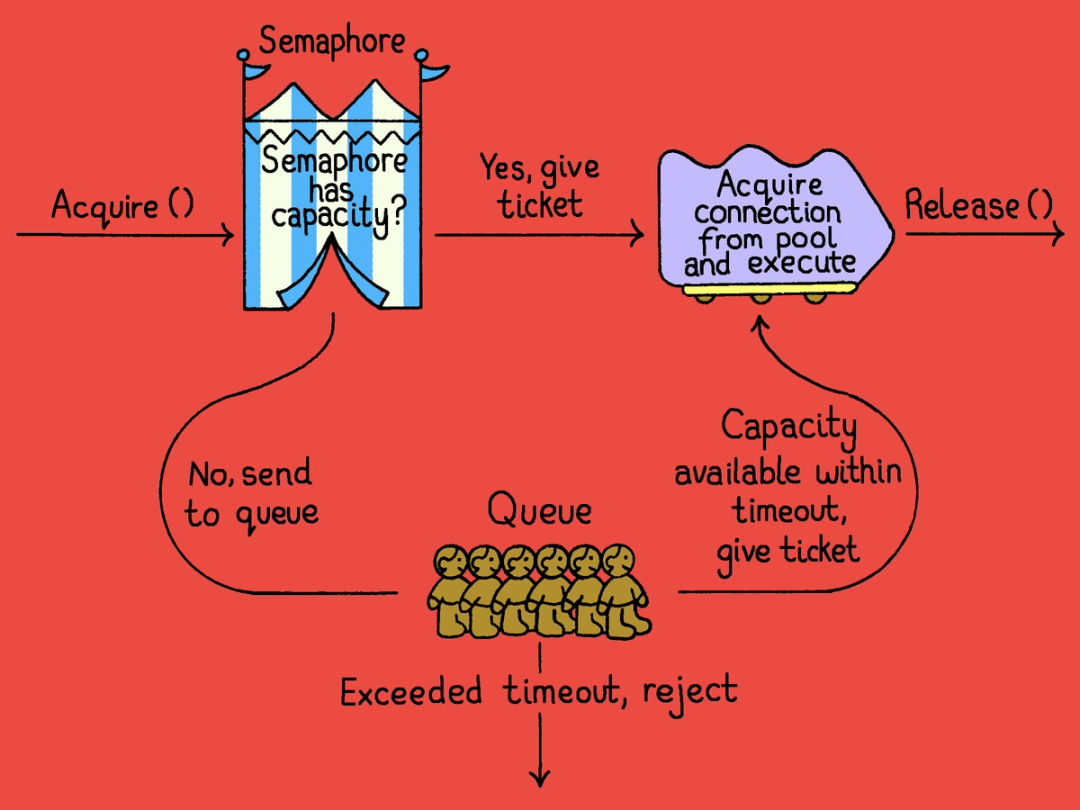
- Admission control: Before the query reaches the database, PGKeeper uses the request’s metadata to decide whether to admit or reject it based on current capacity.
- Connection pool: Once admitted, the request gets a connection from a managed pool. PGKeeper governs connection creation and destruction rates, maintains the pool's health through warming and cooling mechanisms, and guarantees that connections are returned to the pool in a sanitized state to prevent unnecessary churn.
- Query execution: The query is executed against the underlying PostgreSQL instance, and the results are streamed back to the client.

Connection management
PostgreSQL operates on a process-per-connection model. Every client connection instantiates a dedicated backend process on the server, which carries its own memory allocation, session state, and query plan cache—connections are expensive to create and stateful. These costs make connections worth protecting. A pooler plays a critical role in managing connection lifecycles and minimizing churn. The mechanisms below are how PGKeeper does that.
Pool warming
A new PGKeeper instance with an empty connection pool will experience higher latency when first handling requests, as time is spent establishing connections. PGKeeper solves this with a simple but effective mechanism: pool warming. This feature proactively brings connections online before production traffic is routed to the instance.
Connection creation and teardown rate limiting
Pool warming handles the steady-state case, but it does not protect us during a massive connection churn event. Pool warming will attempt to re-establish the lost connections when the pool is not fully hydrated. Without guardrails, this re-creation could itself become a source of overload.
PGKeeper rate-limits connection creation through a token-bucket mechanism. New connections are only established when a creation token is available, spreading the cost of pool growth over time. This prevents bursts of connection creation from overwhelming Postgres, particularly during recovery from churn events, where simultaneous query replanning across new connections can saturate CPU and prolong overload.
PGKeeper uses bradenaw/backpressure, a Go library for prioritized load management authored by Figma alumnus Braden Walker. It provides numerous primitives. We adopt two: a rate limiter (a token-bucket that refills at a fixed rate up to some burst capacity) and a semaphore (which bounds concurrent work rather than rate). Both support priority levels, so higher-priority requests are served first when capacity runs low, and both use CoDel to drop stale requests under sustained overload. PGKeeper uses the rate limiter for connection creation and teardown, and the semaphore for admission control.
The same principle applies to teardown. During our upgrade from PostgreSQL 13.21 to 13.22, we discovered that mass connection closure during pool shutdown also drove significant CPU saturation on the database host. PGKeeper therefore also rate-limits connection destruction, ensuring that connection pool shutdown does not itself become a source of instability.
Connection churn avoidance
PGKeeper implements three mechanisms to ensure connections are cleaned up and reused rather than discarded.
- Bounded exhaust: When a client does not fully consume a result set, the connection may retain server-side state such as open cursors or buffered rows. PGKeeper drains up to 100 remaining rows before returning the connection to the pool. This is enough to rescue the vast majority of incomplete reads (P99 of our queries return fewer than 5 rows), while avoiding unbounded work on the outliers.
- Auto rollback: If a connection is released while a transaction is still in progress, PGKeeper automatically issues a ROLLBACK before returning the connection to the pool. Without this, the connection would carry uncommitted transactional state, making it unsafe to reuse and forcing the pool to discard it.
- Context cancellation handling: The Postgres wire protocol has no native mechanism for a client to signal that it’s no longer interested in the result of an in-flight query, short of opening a second connection and issuing a cancellation from there. PGKeeper handles this by accepting a context from the client through its gRPC interface and translating cancellation into Postgres-native operations. When a client cancels a request, PGKeeper returns an empty result to the caller immediately and handles the actual connection cleanup in the background. Because P95 of our queries complete within 2 ms, PGKeeper waits briefly before initiating cancellation, avoiding unnecessary overhead for queries that are likely to complete on their own. If the query does not complete within this waiting window, PGKeeper issues a
pg_cancel_backend()call through a dedicated cancel-only pool (kept separate so cancellations don’t monopolize the main pool). The return of thepg_cancel_backend()call only ensures the kill signal has been enqueued, not necessarily delivered and handled. So, we need to force the target backend to get scheduled and handle the signal. Thus, we run a lightweightSELECT 1to flush any pending kill signals immediately after the cancel invocation. The connection then goes through the normal bounded exhaust and auto rollback steps before being returned to the pool.
These mechanisms were born from hard-won lessons operating Postgres at scale. Since deploying PGKeeper's connection management, we have not experienced a single massive connection churn incident. Knock on wood.
Admission control
At scale, overload is inevitable: Incoming demand exceeds available capacity and the system cannot serve every request successfully within a reasonable time. The question is not whether to shed traffic, but how. Blindly admitting requests leads to a vicious cycle where queues grow, latency spikes, and failure cascades across unrelated workloads. Conversely, indiscriminate rejection wastes work, extends downtime, and results in a poor end-user experience.
The system must define how it operates when capacity is constrained, and there are always tradeoffs. With Figma’s traffic patterns, historical incidents, and operational requirements in mind, we aligned on the following design principles for admission control:
- Optimize for the end-user experience. During overloaded situations, we should try to keep actions like opening a file, loading a document, or saving edits highly available and responsive. On the other hand, asynchronous batch processing jobs and other lower-priority workflows can tolerate temporary degradation.
- Solve for concurrency-based load. Knowing that no solution could cover all problems, we focus on the most frequent source of overload at Figma: an unexpected spike in the volume of concurrent requests.
- Be adaptive and dynamic. Because we often see traffic patterns that fluctuate greatly, and are undergoing a period of intense scale, we didn’t want static thresholds or a system that needed constant manual adjustment. Whatever mechanisms we choose should be self-balancing.
- Make decisions fast. Admission control runs in the critical path of every database request, so any system we implement must exhibit low (ideally negligible) latency overhead.
V1: Priority-based admission control
We started with a semaphore, which provides a straightforward mechanism for bounding concurrency. By defining a fixed capacity, we can ensure the database never serves more than a maximum number of concurrent connections.
When a request arrives, PGKeeper attempts to acquire a semaphore slot. If capacity is available, the request proceeds. If the limit has been reached, we have the choice to immediately reject the request or queue it. Both options have tradeoffs.
Immediately rejecting is often inefficient. Clients are extremely likely to retry relatively soon, so the system pays for the rejection and then pays again to handle the retry. Database pool capacity is typically sized for average peak load; when traffic spikes above that, immediately rejecting leaves us with no room to make more sophisticated choices in our favor.

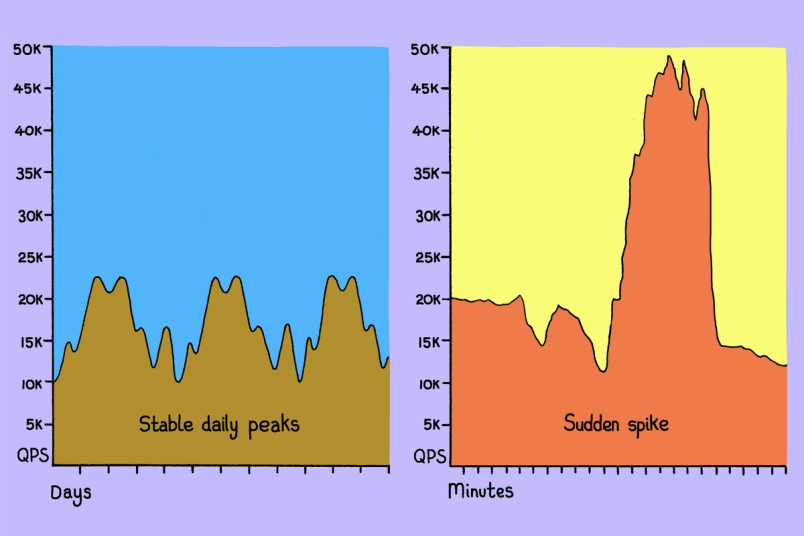
For short-term spikes, queuing is a more graceful response. Rather than rejecting excess work immediately, the system can temporarily hold requests while capacity recovers.

But queueing has its own failure mode, and we’d seen it before with PgBouncer. During a sustained overload, the queue fills faster than capacity can drain it, and requests sit there long enough that the work they represent stops mattering. Picture a user waiting on a slow page load. After a few moments of nothing happening, they hit refresh; now there are two requests in the queue, but the original one is no longer meaningful. At scale, the queue fills with stale requests and the system struggles to clear the backlog.
A more detailed explanation of Controlled Delay and adaptive LIFO can be found here.
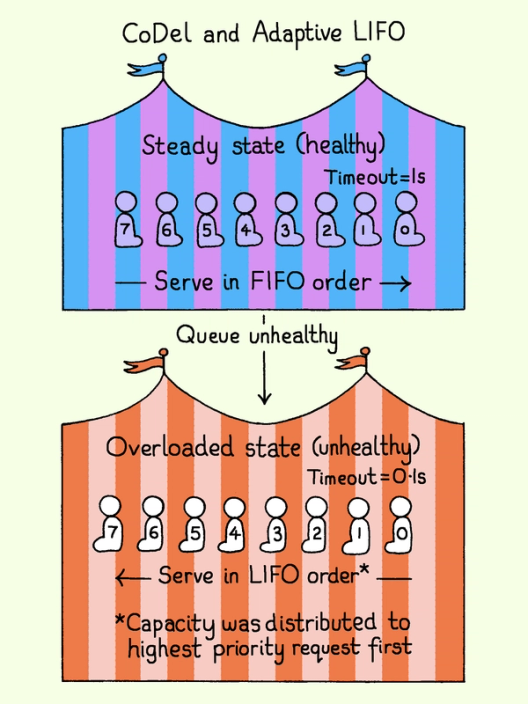
An ideal queuing mechanism would absorb short-term pressure and maximize the value of work under limited capacity. To accomplish this, we adopted the CoDel algorithm combined with adaptive LIFO scheduling.
The system's health is determined by the state of its request queue. A healthy, non-overloaded state exists when the queue is usually empty, allowing requests to be processed in a standard First-In, First-Out (FIFO) order.
Conversely, the system is defined as overloaded when the queue remains non-empty for an extended duration during periods of heavy traffic spikes. To aggressively shed this excess work and rapidly drain the backlog, the system switches its processing order to Last-In, First-Out (LIFO) and employs shorter permitted time in the queue, ensuring older backlog requests are dropped more quickly than usual.

So far we've talked about how PGKeeper handles capacity pressure, but none of that addresses which requests get served when the system is under pressure. All traffic at Figma is tagged with a priority. Higher priorities correspond to critical user flows, while lower priorities represent background jobs or auxiliary workflows. (Requests tagged with high priority undergo careful review before being approved to receive that designation.) During overload, PGKeeper admits requests in priority order, preserving the user experience as much as possible.
PGKeeper enforces this ordering through a self-adjusting mechanism known as debt, a feature of the backpressure library we adopted. Whenever a higher-priority request can’t immediately acquire a semaphore ticket, the system assigns debt to all lower-priority traffic tiers. That debt has to be paid: A request from a lower-priority tier can only acquire a token if there's enough capacity for both the request and the accumulated debt against its tier. Debt decays over time, and pays down faster when higher-priority traffic is succeeding. This dynamic approach ensures that higher-priority requests are favored during periods of overload, without permanently allocating capacity to any specific class of traffic.
In production, this approach proved effective during overload incidents. High-priority traffic stayed available while lower-priority requests were shed and mostly retried successfully, invisible to end users.

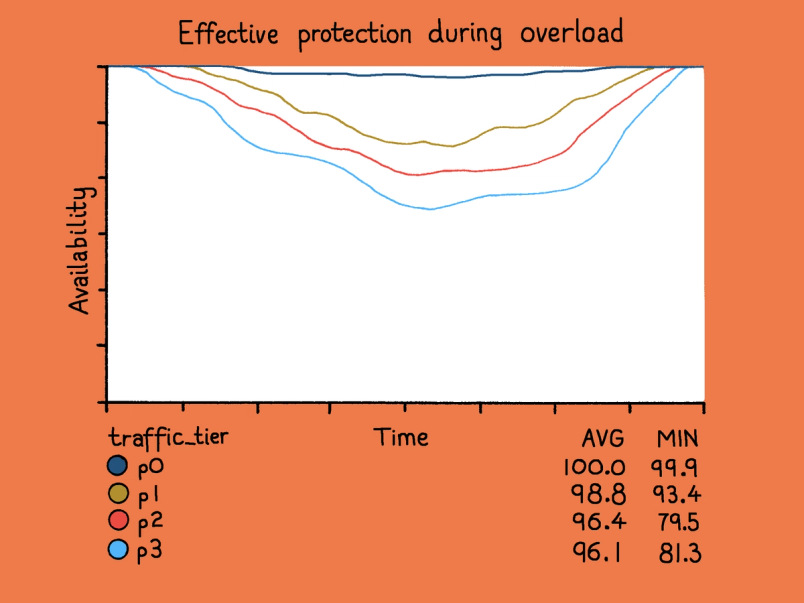
V2: Multi-dimensional fair sharing
The priority-based semaphore worked well, but it left a gap. A single dominant workload could consume the majority of available concurrency within its priority tier and starve out traffic at the same level. An unexpectedly popular new feature, or a DDoS attack, could exhaust the high-priority budget before admission control rebalanced resources. While lower-priority traffic would still be shed first, unrelated workloads at the same priority would experience degradation.
Real traffic varies along multiple axes: authentication status, request source, client, user type, and so on. Under overload, we want capacity to be allocated proportionally across these categories, ensuring that no single workload can monopolize its tier.
So we built a weighted min-max fair share algorithm. Assuming there is a finite resource and multiple consumers demanding more than the available amount, fair sharing works by giving each consumer a baseline allocation. Consumers who don’t need their full share release the rest into a common pool, and consumers who need more than their share can draw from that pool, up to a limit. The result is that no one starves, and no one hogs the resource either.

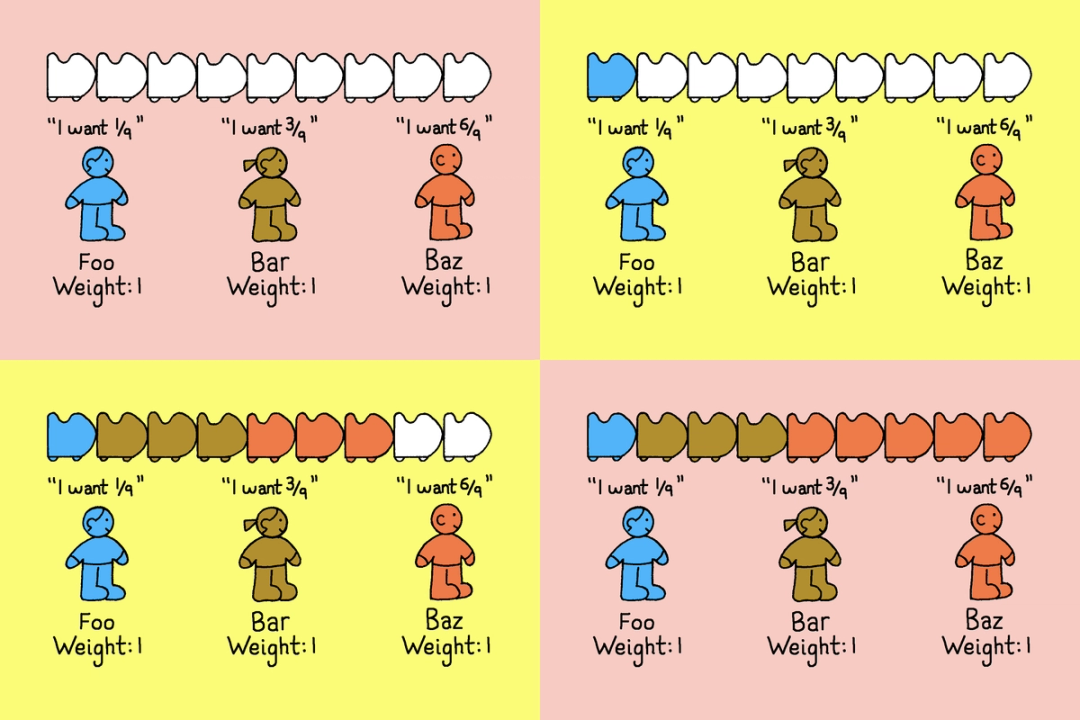
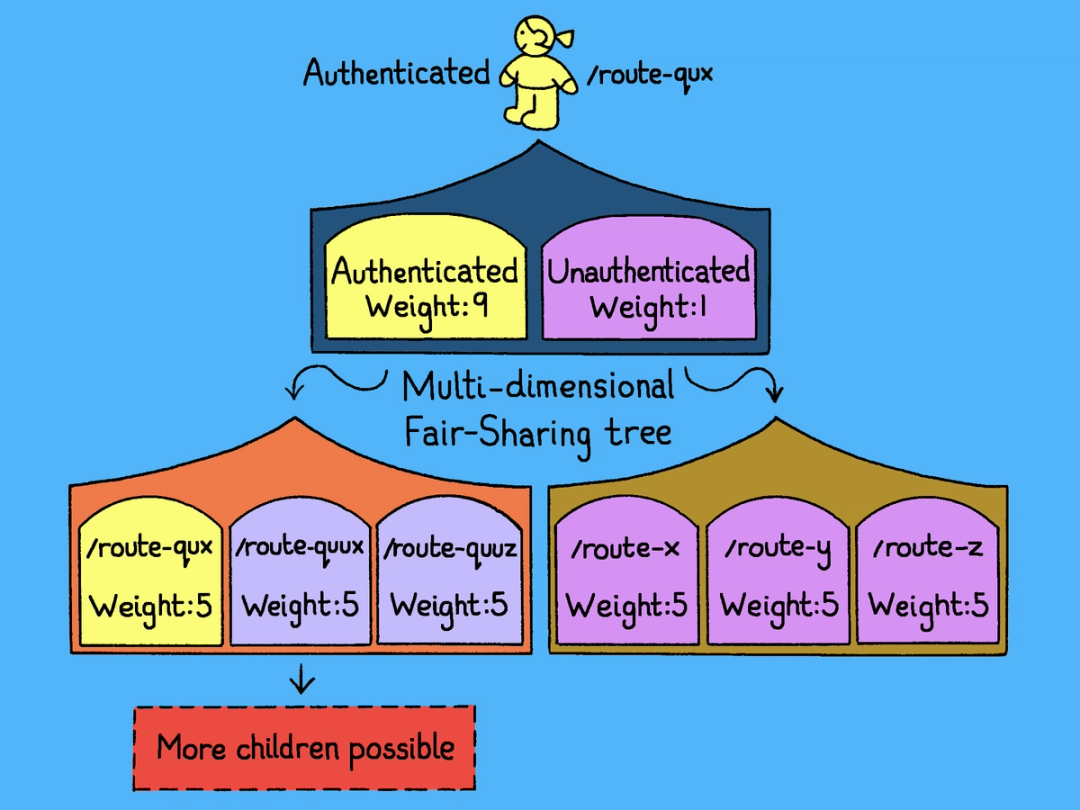
In PGKeeper, the resource is database concurrency capacity and the consumers are categories of traffic. A category might be “authenticated traffic to the comments endpoint” or “unauthenticated traffic to the search endpoint.” Because traffic varies along multiple axes at once, we represent these categories as a tree, with each level corresponding to a different dimension. The diagram below shows a simplified two-level version: The top level splits by authentication status (with authenticated traffic weighted much more heavily, since it’s almost always more important), and the second level splits each of these by route.
Capacity is allocated from the root downward. At each node, the available concurrency is divided across child categories according to their weights. This process repeats recursively through the tree.
This hierarchical structure allows PGKeeper to enforce fairness simultaneously across multiple dimensions, preventing any single workload from monopolizing database capacity.

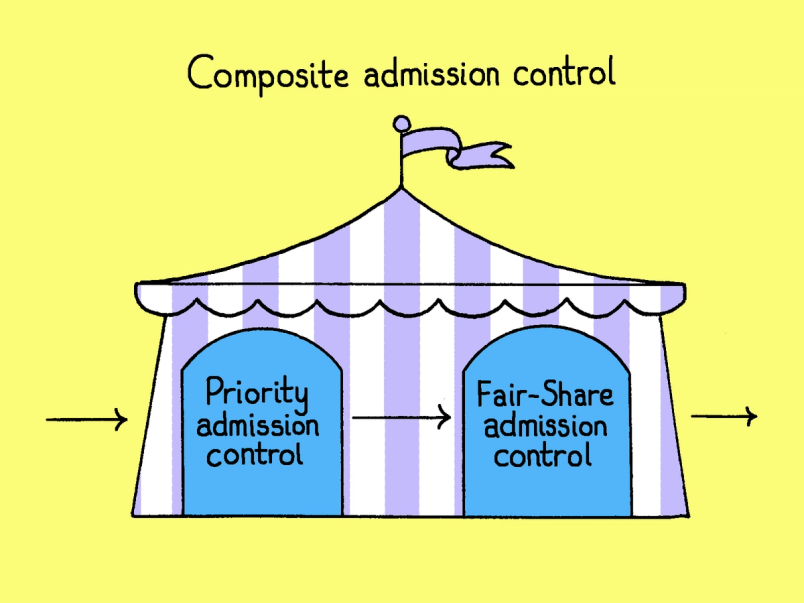
PGKeeper comprises both of the controllers we’ve discussed. Every request first passes through priority admission control, which uses the semaphore-with-debt mechanism to favor high-priority traffic when the database is under contention. If a request clears that, it then passes through the fair-sharing tree, which checks whether the request's category has room within its own allocation. A request only proceeds if both controllers admit it.

Symbiotic client relationship
Admission control significantly improves system stability, but rejection alone cannot prevent overload at sufficiently high request rates. At some point, the only way to prevent sustained pressure is for clients to send less traffic.
PGKeeper returns informative error codes that indicate overload rejections, and provides an AdaptiveThrottle package that clients can use to back off when encountering errors (paired with exponential backoff and retry strategies). Using this feedback loop, the server and its clients converge toward a stable request rate without any central coordination.
Limitations
PGKeeper doesn’t eliminate every failure mode. Three classes of problems remain:
- Expensive queries: Admission control primarily protects against excessive concurrency, not the cost of individual queries. A single poorly behaved query can still monopolize database resources. For example, an unexpected sequential scan on a large table or a poor query plan produced by the Postgres optimizer can consume significant CPU or I/O even when concurrency is low. We reduce the likelihood of this failure mode through an adjacent project, Guardrails, which flags inefficient queries at CI time so they never reach production.
- Skewed load distribution: Per-instance load management only works if traffic is evenly distributed across PGKeeper pods, and load balancing is rarely perfect—uneven distribution leaves some pods under more pressure than others. Today we mitigate this by placing PGKeeper replicas behind an NLB and having clients establish multiple gRPC connections, which helps spread traffic more evenly across pods. A service mesh would give us stronger guarantees, and that’s where we’d like to go.
- Small connection pools: Multi-dimensional fair sharing needs enough total concurrency to slice across categories. With a small connection pool, there just aren’t enough slices to go around. Fairness becomes coarse, and admission control has to fall back on simpler prioritization.
Safe rollout
Migrating production traffic from PgBouncer to PGKeeper without any degradation in performance or reliability required a deliberate, incremental rollout strategy, and thorough disaster scenario tests.
Disaster readiness testing (DRT)
Before rolling out to production, we ran two kinds of disaster readiness tests.
- Load testing: We load-tested PGKeeper at 3× our peak production QPS to check its vertical scalability and measure how much latency the gRPC layer added on top of raw PgBouncer. The overhead was sub-millisecond—well within what we could afford for the gains in load management and observability we were getting in return.
- Synthetic load generators: We couldn't predict every traffic pattern PGKeeper would see in production, but we could replay the ones that had hurt us before. We built synthetic load generators from past incidents and ran them against PGKeeper, tuning parameters and refining the algorithm until the system held up under each one.
Rollout ordering
A bad rollout of PGKeeper could have taken down database availability for the entire platform, so we designed the deployment to bound the blast radius of any failure. We classified every database instance group by criticality and rolled them out in strict order, from lowest-risk to highest-risk groups.
We began with a single replica in each cluster, ranked by criticality. Starting with one replica was low-risk because DBProxy hedges replica requests; if the PGKeeper replica had problems, traffic would be served by the others still behind PgBouncer. From there, we gradually expanded to include all replicas. This methodical approach gave us a safe way to validate PGKeeper's behavior under live production traffic before moving to configurations with higher potential impact. Once all replicas were rolled out, we proceeded to non-critical primaries, and eventually, all primaries.
Automatic error detection
Even with a careful rollout ordering, we needed a mechanism to detect problems and react faster than a human operator could. We implemented a sliding window error detector that continuously evaluated the error profile of recent traffic in the DBProxy layer. If the error rate exceeded a threshold for a sustained number of windows, DBProxy would automatically flip traffic back to PgBouncer. This mechanism proved its value early. During the first phases of rollout, the detector flipped the traffic back to PgBouncer a few times and helped us avoid availability issues.
Flipping all traffic back to PgBouncer at once means a sudden surge of new connections against PgBouncer, which could itself cause instability. But a brief period of unavailability during the switchback was preferable to an extended availability issue caused by a malfunctioning PGKeeper continuing to serve traffic.
From bouncer to keeper
Since the full rollout, Figma's database SLO, measured against core user experience availability, has held at above 99.99%. In Q4 2025 alone, PGKeeper prevented more than 20 incidents that would otherwise have caused user-visible outages.
PGKeeper began as an effort to replace an aging connection pooler. It has since become a foundational component of Figma's database infrastructure, serving as the primary line of defense between our applications and PostgreSQL. Owning this layer comes with tradeoffs, including maintenance burden, on-call responsibility, and operational overhead, but the gains in reliability, observability, and control have made those tradeoffs worthwhile.
We're hiring engineers!
Learn more about life at Figma, and browse our open roles.
We would like to thank Braden Walker for the inspiration and the powerful backpressure library that informed much of this work. We are also grateful to our partner teams, including Compute, Deploys, Traffic, Application Platform, DevEx, and Storage Products, for their collaboration and support throughout the design and rollout of PGKeeper.
Finally, this work would not have been possible without the PGKeeper team: Gustavo Mezerhane, Bashar Al-Rawi, Tanay Lathia, Mehant Baid, Manish Jain, and Dylan Visher.
Lihao is a software engineer on the Storage Platform team, primarily supporting Figma’s database reliability and scalability initiatives.
Tim is a software engineer on the Storage Platform team. His experience encompasses various layers of the database stack.
Mehant is the engineering manager for Figma’s Database team. He previously worked at Dropbox, building out their petabyte scale metadata storage systems.